libpcap离线包排序
本文最后更新于:2020年10月25日 下午
libpcap是unix/linux平台下的网络数据包捕获函数包,大多数网络监控软件都以它为基础。原先的在python下用scapy读包效率过低,故转用在C下由libpcap实现读包排序。
libpcap安装
wget https://www.tcpdump.org/release/libpcap-1.9.1.tar.gz
tar zxvf libpcap-1.9.1.tar.gz
cd libpcap-1.9.1/
./configure
sudo make
sudo make installlibpcap的一些关键函数
1.获取网络接口
char * pcap_lookupdev(char * errbuf)
返回第一个合适的网络接口的字符串指针,如果出错,则errbuf存放出错信息字符串,errbuf至少应该是PCAP_ERRBUF_SIZE个字节长度的
2.释放网络接口
void pcap_close(pcap_t * p)
关闭pcap_open_live()获取的pcap_t的网络接口对象并释放相关资源
3.读取本地pcap文件
pcap_t * pcap_open_offline(const char *fname, char *errbuf)
函数打开保存的数据包文件,用于读取,返回文件描述符
fname参数指定了pcap文件名
errbuf依旧是函数出错的时候返回错误信息
4.获取数据包
int pcap_loop(pcap_t * p, int cnt, pcap_handler callback, u_char * user)
第一个参数是第2步返回的pcap_t类型的指针
第二个参数是需要抓的数据包的个数,一旦抓到了cnt个数据包,pcap_loop立即返回。负数的cnt表示pcap_loop永远循环抓包,直到出现错误。
第三个参数是一个回调函数指针,它必须是如下的形式:void callback(u_char * userarg, const struct pcap_pkthdr * pkthdr, const u_char * packet)
- 第一个参数是pcap_loop的最后一个参数,当收到足够数量的包后pcap_loop会调用callback回调函数,同时将pcap_loop()的user参数传递给它
- 第二个参数是收到的数据包的pcap_pkthdr类型的指针
- 第三个参数是收到的数据包数据
5.保存数据包
pcap_dumper_t *pcap_dump_open(pcap_t *p, const char *file)
函数返回pcap_dumper_t类型的指针,file是文件名,可以是绝对路径
void pcap_dump_close(pcap_dumper_t *p)
用来关闭pcap_dump_open打开的文件,入参是pcap_dump_open返回的指针
int pcap_dump_flush(pcap_dumper_t *p)
刷新缓冲区,把捕获的数据包从缓冲区真正拷贝到文件
void pcap_dump(u_char * userarg, const struct pcap_pkthdr * pkthdr, const u_char * packet)
输出数据到文件,与pcap_loop的第二个参数回调函数void callback(u_char * userarg, const struct pcap_pkthdr * pkthdr, const u_char * packet) 形式完全相同,可以直接当pcap_loop的第二个参数;
排序思路
提取特征
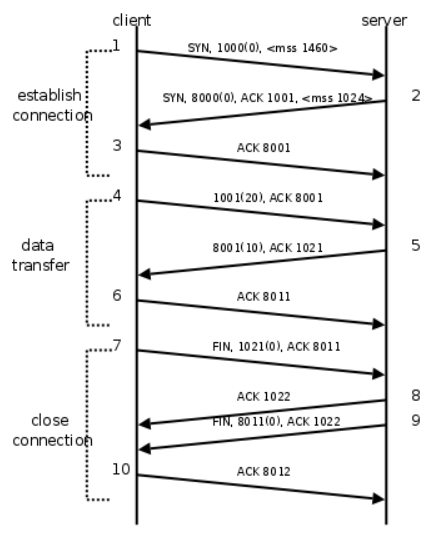
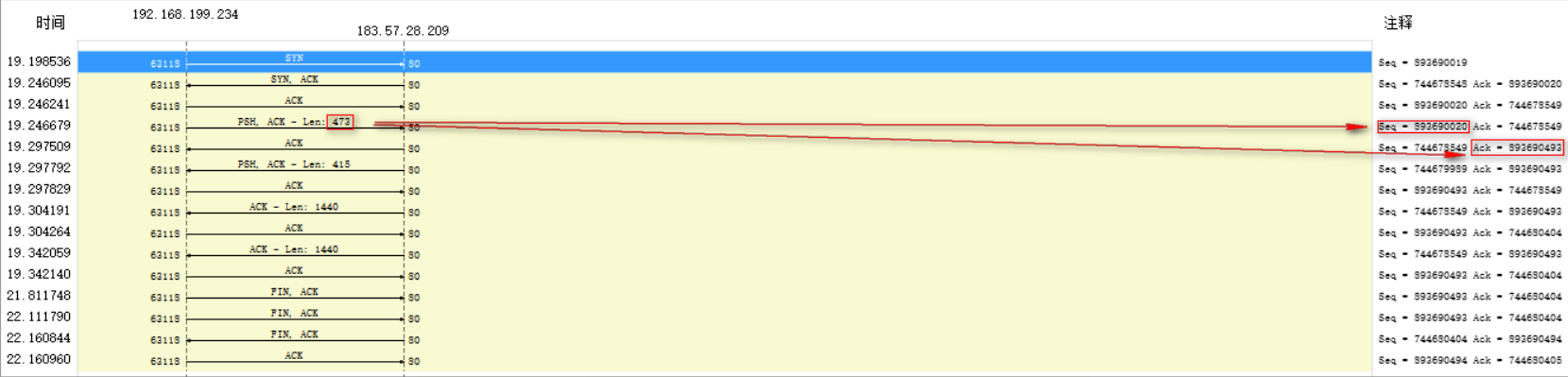
上面两张图相当关键,是提取出排序思路的要点。整体上可以得出如下的排序原则:
- 对于一个流来说,
seq是呈递增趋势的 - 存在
ack包长度为0,对于一个流来说,为0的包接下来的包的seq和本次相同,直至传来有长度的包 - 如果包为
syn,对于一个流来说,即使这个包为0,下一个来的包的seq+ 1 - 对于一个seesion的包来说,两个之间的
ack和seq存在对应关系,应满足如下的关系:(a、b指一个session中两个不同的流)- a的
ack小于或等于b的seq - a的
seq小于b的ack
- a的
排序特征总结
根据上述说明,我们可以得出一些排序时我们需要得出的信息:
源IP地址、目标IP地址这两者用于来在一个session中区分出两个不同的流,仅需比较一个就够了。同时我们对session排序需要严格控制插入的规则,应该只允许一个流的插入到另一个流之中,避免出现混乱。
seq、next_seq这两者用于一个流的排序。
next_seq实际为seq值加上包的长度len,如果len为0正常情况下seq和next_seq相同,但是在出现包为syn时,即使len为0,next_seq也要为seq+ 1ack用于session的排序中,确定一个流的包在何时插入至另一个流中。有时需要结合
seq判断
分析流量包
我们使用libpcap所获得的流量包是裸包,即最原始的包信息,我们需要对获得的包手动进行分析才能得到我们需要的信息。
调用 pcap_loop 获得的包需要在 callback 函数中进行我们的分析。后两个参数是包的信息关键,原始包信息就在最后一个参数 packet 中,而包的长度则由前一个参数 pkthdr 结构里定义,其结构如下:
struct pcap_pkthdr
{
struct timeval ts; /* time stamp */
bpf_u_int32 caplen; /* length of portion present */
bpf_u_int32 len; /* length this packet (off wire) */
};在分析过程中我们主要关注 packet
以太网帧头
packet 的第一部分为以太网帧头,排序过程中我们不关心它,不进行解析,只需要知晓它的长度跳过即可。它的长度为 ETH_HLEN ,为14字节
IP头
以太网帧头后的部分为IP头,我们通过 netinet/ip.h 中定义好的 iphdr 结构来解析它。结构如下:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*The options start here. */
};通过以下代码计算偏移量,我们就可以获得所需要的IP头结构:
struct iphdr *ip_header = (struct iphdr *)(packet + ETH_HLEN);我们关注的IP头信息为 源IP地址 和 目标IP地址 ,这两个信息为IP头中的 saddr 和 daddr ,但是直接读取这两者我们不能得到想要的 x.x.x.x 的结构。为了得到想要的内容,我们还需要借助 arpa/inet.h 中定义好的结构 sockaddr_in 。结构如下:
struct sockaddr_in
{
sa_family_t sin_family; //地址族(Address Family)
uint16_t sin_port; //16位TCP/UDP端口号
struct in_addr sin_addr; //32位IP地址
char sin_zero[8]; //不使用
};
struct in_addr
{
In_addr_t s_addr; //32位IPv4地址
}所以,将 saddr 和 daddr 赋给上述结构中的 s_addr ,再调用 inet_ntoa() 函数,就得到了我们需要的两个地址。
char *inet_ntoa(struct in_addr in)将一个32位网络字节序的二进制IP地址转换成相应的点分十进制的IP地址(返回点分十进制的字符串在静态内存中的指针)。
所在头文件:
arpa/inet.h
TCP头
IP头后的部分位TCP头,我们通过 netinet/tcp.h 中定义好的 tcphdr 结构解析它。结构如下:
typedef u_long tcp_seq;
/*
* TCP header.
* Per RFC 793, September, 1981.
*/
struct tcphdr {
u_short th_sport; /* source port */
u_short th_dport; /* destination port */
tcp_seq th_seq; /* sequence number */
tcp_seq th_ack; /* acknowledgement number */
#if BYTE_ORDER == LITTLE_ENDIAN
u_char th_x2:4, /* (unused) */
th_off:4; /* data offset */
#endif
#if BYTE_ORDER == BIG_ENDIAN
u_char th_off:4, /* data offset */
th_x2:4; /* (unused) */
#endif
u_char th_flags;
#define TH_FIN 0x01
#define TH_SYN 0x02
#define TH_RST 0x04
#define TH_PUSH 0x08
#define TH_ACK 0x10
#define TH_URG 0x20
u_short th_win; /* window */
u_short th_sum; /* checksum */
u_short th_urp; /* urgent pointer */
};通过以下代码计算偏移量,我们就可以获得所需要的TCP头结构:
struct tcphdr *tcp_header = (struct tcphdr *)(packet + ETH_HLEN + sizeof(struct iphdr));我们关注的信息为 seq 、 ack 、 next_seq 。其中, seq 、 ack 是结构中给我们的,通过 th_seq 、 th_ack ,调用 ntohl() 函数,我们就可以得到需要的两个值。
uint32_t ntohl(uint32_t netlong)将一个无符号长整形数从网络字节顺序转换为主机字节顺序。
所在头文件:
arpa/inet.h
next_seq 是接下来的重头戏,因为结构本身并没有给出这个值,需要我们自己去计算得出。按照之前的的分析,这个值是 seq 的值加上包的长度。IP头结构中的 tot_len 可以给我们帮助,只需要用这个长度减去IP头长度和TCP头长度,这两个的长度就需要我们自己获得了。
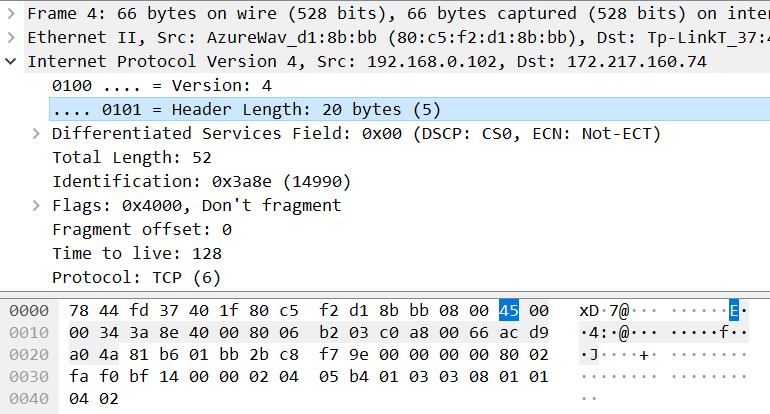
借助wireshark,我们可以看到IP头的长度在原始数据包中是有所记录的,就在包的第15个字节的后一位,该值*4即为IP头长度

同样的,可以看到TCP头的长度在原始数据包中有记录,在包的第47个字节的前一位,该值*4即为TCP头长度
通过以下代码计算偏移量,我们就可以获得包的长度了:
len = ntohs(ip_header->tot_len) - ((int)packet[46])/16*4 - ((int)packet[14])%16*4; next_seq 的值即为 seq + len
排序数据结构
现在我们已经获得了排序所需要的信息,接下来就需要构建一个便于我们排序的结构来进行排序。为了便于我们的插入排序,构建链表是一个不错的选择
struct packetnode{
struct pcap_pkthdr *pkthdr;
u_char *packet;
char *srcip;
char *dstip;
u_long seq;
u_long ack;
u_long next_seq;
};上面的节点结构用来处理数据包,便于后续排序。 pkthdr 和 packet 是原始抓到的数据包,也是我们后续要保存至文件的东西。后面的五个就是在上面分析流量包的环节我们排序所需要的信息,将它保存在这个节点结构中
struct packlist{
struct packetnode *data;
struct packlist *left;
struct packlist *right;
};上面的链表结构用来构建链表,有 left 和 right 用来进行查询和插入
排序流程图
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!